How Tesla uses neural network at scale in production
This notebook summarizes the recent spectacular talk of Andrej Kaparthy showing how Tesla is using neural network at scale in production.



- Overview
- HydraNet
- Data engine and operation vacation
- Evaluation metrics
- Modeling: Bird's Eye View networks
At the Scaled Machine Learning Conference this year 2020, Andrej Kaparthy - Director of AI at Tesla - has given a spectacular talk about how Tesla is applying AI into their system. There are so much information and distilled knowlege came out from this talk which made me can not resist to write this blog post. If you want to access to other talks from Scaled Machine Learning Conference, go here.
Overview
The talk is about AI for Full-Self Driving where Andrej talked about how Tesla are improving the safety and convenience of driving, how they deploy deep learning into production and supports all the features of autopilot today, how the neural net is eating through the software stack and how they are putting vision and AI at the front and center of this effort.
Full self-driving is a non-trivial task which requires you to not only follow the driving law but also to satisfy massive number of users. Tesla has built their cars to be like a real computer with eyes(cameras) on it. Beside the main functions of self-driving, they also have other great functionalities such as active safely (e.g auto detect pedestrians even when self-driving mode is off) and auto parking (auto search for the parking lot).
Different with other companies where Lidar is used as car's eyes, Tesla is using vision-based approach with cameras. The advantage of this approach is its scalability where cameras can be easily installed in millions of car.
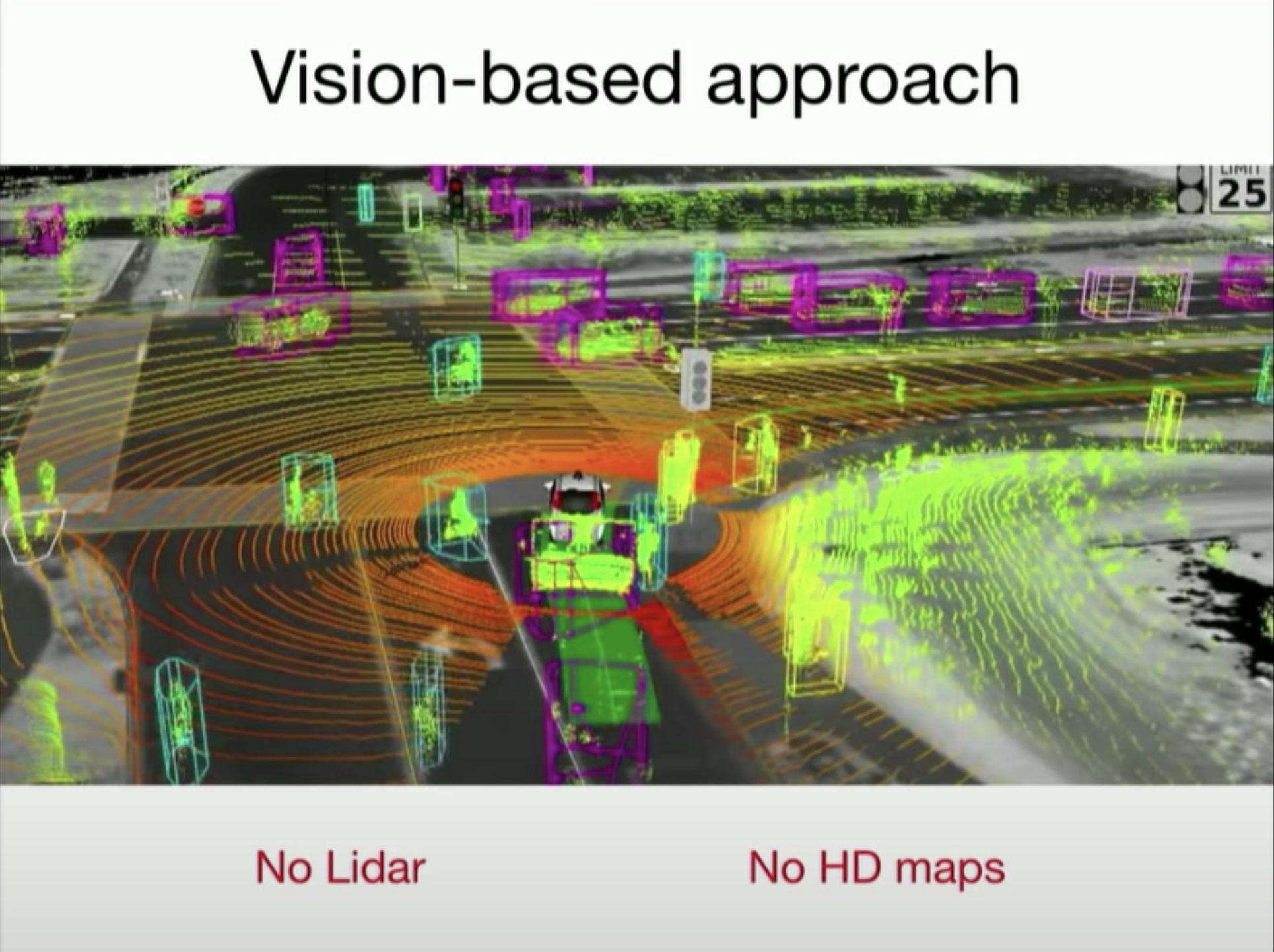
HydraNet
Using the images from cameras, Tesla AI team has built a very large network for detecting objects that their cars have to encounter on the street. As you can see the image on the left below, in order to make decision the car needs to detect a lot of objects around it such as lane lines, static objects, road signs, crosswalks, etc. Their huge object detection network, HydraNet, has shared backbone and multiple heads, each of them is responsible for a number of tasks. And for each detecting task, there can be multiple subtasks come with it and if we list them out all, the number can be even thousand of tasks.

In order to boost the performance of HydraNet, Tesla needs a lot of data. So you have thousand of tasks to solve and each of them requires thousands of images. Wouldn't you need thousand of engineer to make it work?
In order to deal with such large amount of work with not so many engineers, Andrej has introduced the concept of operation vacation and data engine.
Operation vacation means the engineers might take vacation while the system still operate well. They have tried to develop as much automation machinery to support the development of new tasks and remove engineers from that loop. The infrastructure has been built so that the labeling team or PMs can actually create new detectors whenever they have new tasks. So the process, from starting point of a new detector to actually deploy it, might have a latency but fully automatic.
Tesla has built infrastructures for classes of task in order to automate as much as possible. Getting an example of a new task detecting caution lights which might be categorized as a landmark task. If this task is a member of task family which Tesla has built infrastructure for, then the things is super easy. They just need to plug-and-play the prototype infrastructure of landmark task and go through the Data Engine.

Data Engine is the process by which they iteractively apply active learning to source additional examples in cases detector misbehaving. For example the task detecting caution lights, first they have to label a seed set of images in order to have a seed set of unit tests. The network head is then trained on current data and if it fails on the test set, they will spin on data engine to get more data and thus improve the accuracy. An approximate trigger will be trained offline and ship to the fleet(the Tesla's million car unit running on the street) in order to source more images in failing scenarios. These harvested images are then labeled and fed into training set. The network is trained again, the test set is enriched as well. These processes are iteractive and they have seen the accuracy has gone like from 40% to 99%.
Breaking down the steps of applying data engine for the task detecting caution lights:
- Init new layer of annotation: CAUTION_LIGHT (LANDMARK)
- Label a seed set of images
- Develop a seed set of unit tests
- Train network head on current data
- While QA does not sign off:
- While unit tests fail:
- Deploy a trigger(an offline trained approximate detector)
to the fleet(millions of Tesla car running on the street)
in order to source more images in failing scenarios.
- Label the resulting images and incorporate them into the training set.
- Retrain network on data
- Enrich/grow set of unit tests
- Deploy to run on the FSD computer
- (Optional) Deploy to the fleet in shadow mode
- Collect telemetry and evaluate the performance of the feature
- Ship feature
In the above part, we have seen the tremendous efforts that Andrej's team has been working on for growing their training set. But Tesla has also placed just as much work into massaging the test set as they do in the training set. They spent a lot of time, inspired by test-driven development, to build out very complicated test set. Their test set is treated like unit tests which has to cover all cases. This set is so important and it is the objective for the whole system improvement. Whether you are going in right or wrong direction, it all depends on the quality of the test set.
A mechanism has been built for creating and massaging the test set. And this set is a growing collection thanks to the fleet running along the street and encounters different problems daily.
Just reporting the loss function or the mean average precision on the test set is not enough for Tesla. Below is an example of test set for stop sign detector which is actually broken down into all these different issues like heavy rain/snow, heavily occluded, tilted stop signs and each of them is tracked separately and is pursued one-by-one with data engine to actually make them work.

Modeling: Bird's Eye View networks
In this part, Andrej talked about how the neural network has to change in order to actually support full self-driving.
The self driving system can not just work with raw predictions from 2d pixel space, it is needed to project them out to some kind of top-down view. A traditional approach is to create occupancy tracker where 2D images are projected into 3D and stitched up across cameras and then across time. This tracker will keep the temporal context and create a small local map which helps the car winds its way thru the parking lot for example(see top left image below).
However, there are a lot of problems doing the stitching because these cameras are pointing in arbitrary directions and it is very hard to align them across cameras. Very difficult to develop.
![]()
So Tesla's AI team has decided to move from occupancy tracker (software 1.0 approach) to BEV Net (software 2.0 approach) and they see typically that works really well.
Briefly remind about software 1.0 and software 2.0 that Andrej has many times mentioned in his previous talks. Software 1.0 is the traditional way of coding where developers directly write the code to create the software.
Software 2.0 is the neural network-based approach where developers indirectly write the code. The optimization algorithm is the one compile data into code. Software 2.0 is extremely useful when the problem is so messy and super hard to code. The trend is moving toward software 2.0 but each of them has their own pros and cons. The best way is still to combine them in a clever way.

As shown in the image above, images from cameras are fed to backbone and then going to a Fusion layer that stitches up the feature maps accross different view and also does the projection from image space to bird eye view. And then you have a Temporal module to actually smooth out these predictions. The BEV Net decoder actually create top-down space. That is how we can directly predict objects in top-down view from camera images.
Most of the things that Andrej has described so far reply primarily on supervise learning where Tesla AI team has spent efforts to create and massage massive dataset. However, he have seen a lot of progress today in self-supervise learning so he wants to leverage some of that to speed up the process and the rate at which they learn from very little supervised data. So let's wait for Andrej's next talk with self-supervised models deployed in Tesla autopilot system.